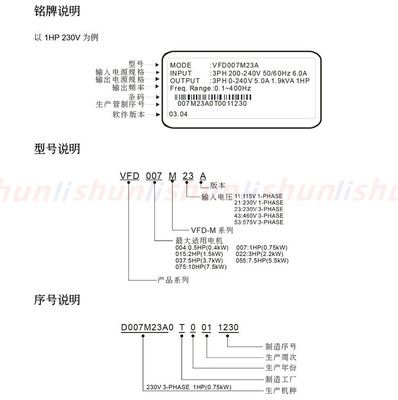
易能變頻器EDS800-2S0007 廣東佛山廠家直銷,特價優惠不容錯過

在工業自動化控制領域,變頻器作為電機驅動與節能的核心部件,其性能與可靠性至關重要。易能變頻器以其穩定的品質和出色的性價比,在市場中贏得了廣泛的認可。其中,EDS800-2S0007型號更是憑借其卓越的性能表現,成為眾多中小型機械設備與生產線的理想選擇。
如今,我們為廣東佛山及周邊地區的工業用戶帶來了一個振奮人心的好消息:易能EDS800-2S0007變頻器正開展廠家直銷特價銷售活動。作為廠家在佛山地區的授權代理商,我們旨在減少中間流通環節,將最實惠的價格直接提供給終端用戶。這不僅意味著您可以用更具競爭力的成本獲得原裝正品設備,更能享受到來自生產源頭的專業服務與技術支持。
EDS800-2S0007變頻器設計緊湊,功能強大,適用于多種通用機械的調速與節能改造。其穩定的矢量控制性能、豐富的接口配置以及便捷的操作界面,能夠有效提升設備運行效率,降低能耗,并延長電機使用壽命。無論是用于風機、水泵,還是傳送帶、攪拌機等設備,它都能提供精準、平滑的控制效果。
選擇本次廠家直銷特價活動,您將獲得多重保障:
- 價格優勢:直銷模式確保價格透明、實惠,真正讓利于客戶。
- 正品保證:所有產品均為原廠生產,杜絕翻新與假冒偽劣,質量可靠。
- 快速供貨:佛山本地現貨儲備,響應迅速,縮短您的采購與設備維護周期。
- 專業服務:提供從選型指導、安裝調試到售后維護的一站式技術服務,解決您的后顧之憂。
我們誠邀廣東佛山及華南地區的設備制造商、系統集成商、工廠設備維護部門以及各界新老客戶垂詢洽談。抓住此次特價直銷機遇,為您的生產設備升級換代或備件采購,注入高性價比的驅動核心。立即聯系我們,獲取專屬報價與詳細技術資料,讓易能EDS800-2S0007變頻器為您的企業高效、穩定運行保駕護航。
如若轉載,請注明出處:http://www.3jfdjh.cn/product/74.html
更新時間:2026-06-16 03:55:09